Titanic Analysis with Machine Learning

Project Summary
This project analyzes the Titanic dataset to predict passenger survival using machine learning techniques. An extensive feature engineering process was performed and several classification models were tested.
Process Overview
Model Comparison
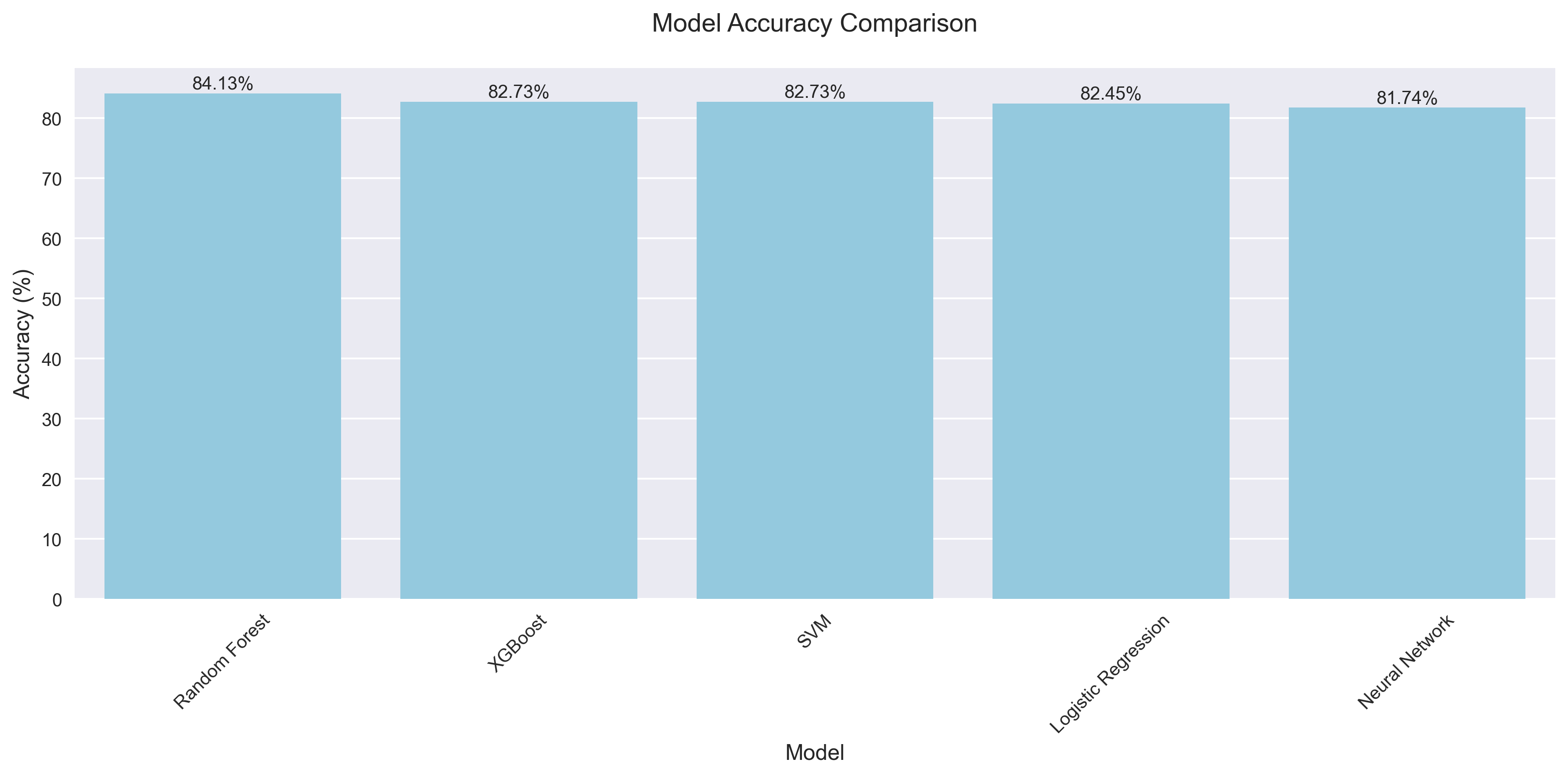
Random Forest showed the best performance with an accuracy of 84.13%, followed by XGBoost and SVM with 82.73%.
Feature Importance
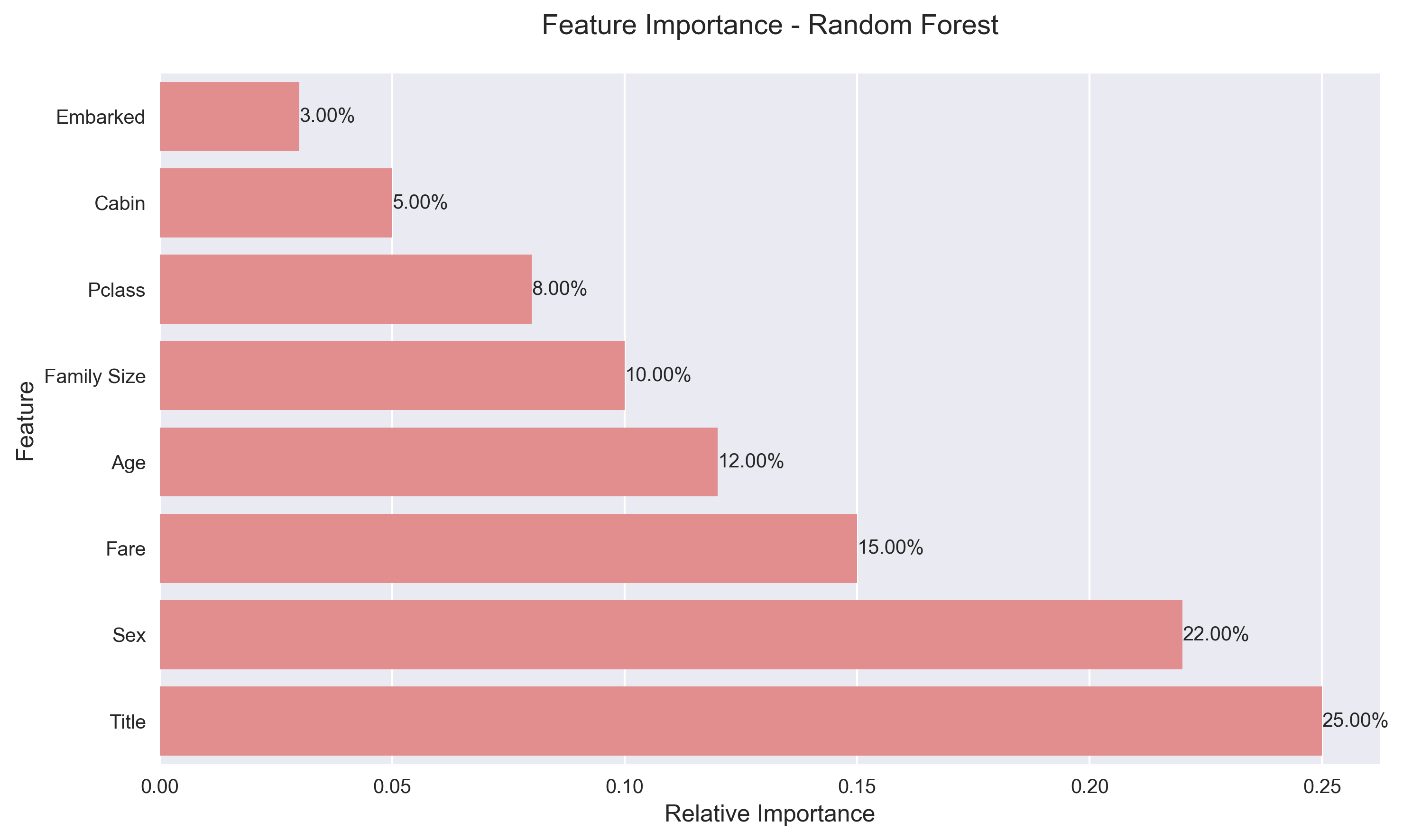
The passenger's title and gender were the most influential factors in survival prediction.
Survival by Class
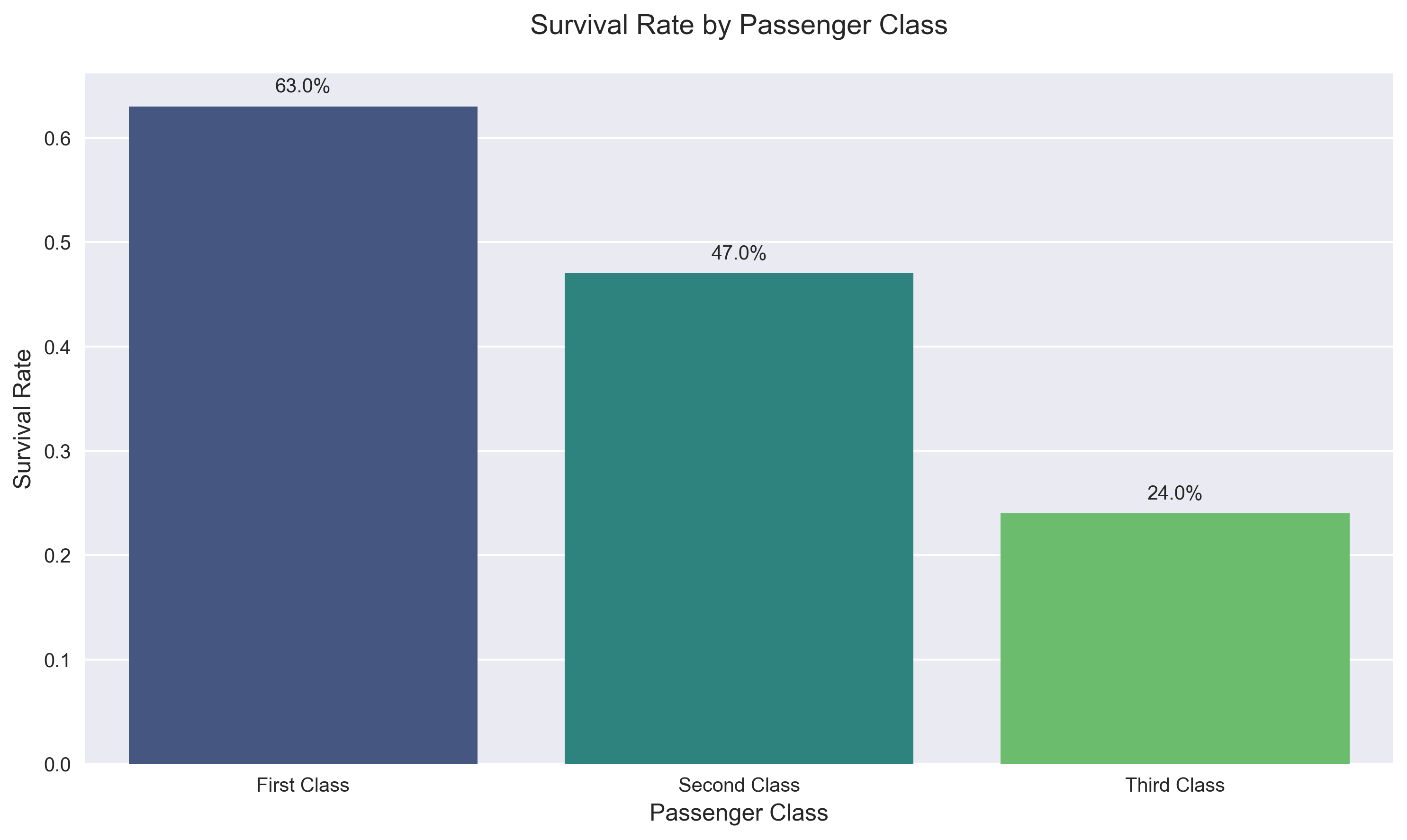
First-class passengers had a significantly higher survival rate (63%) compared to third-class passengers (24%).
Age Distribution
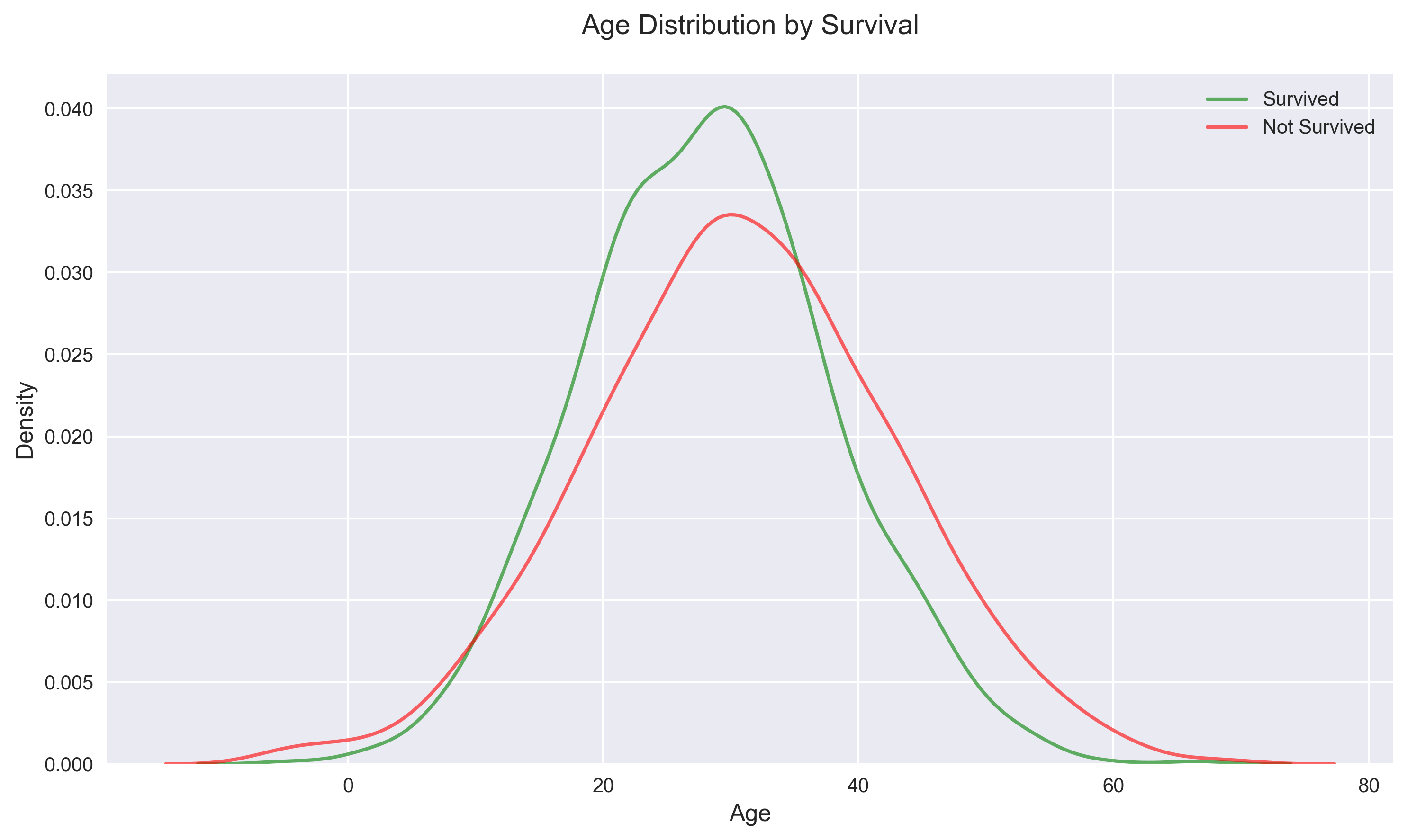
A slight difference in age distribution is observed between survivors and non-survivors.
Confusion Matrix
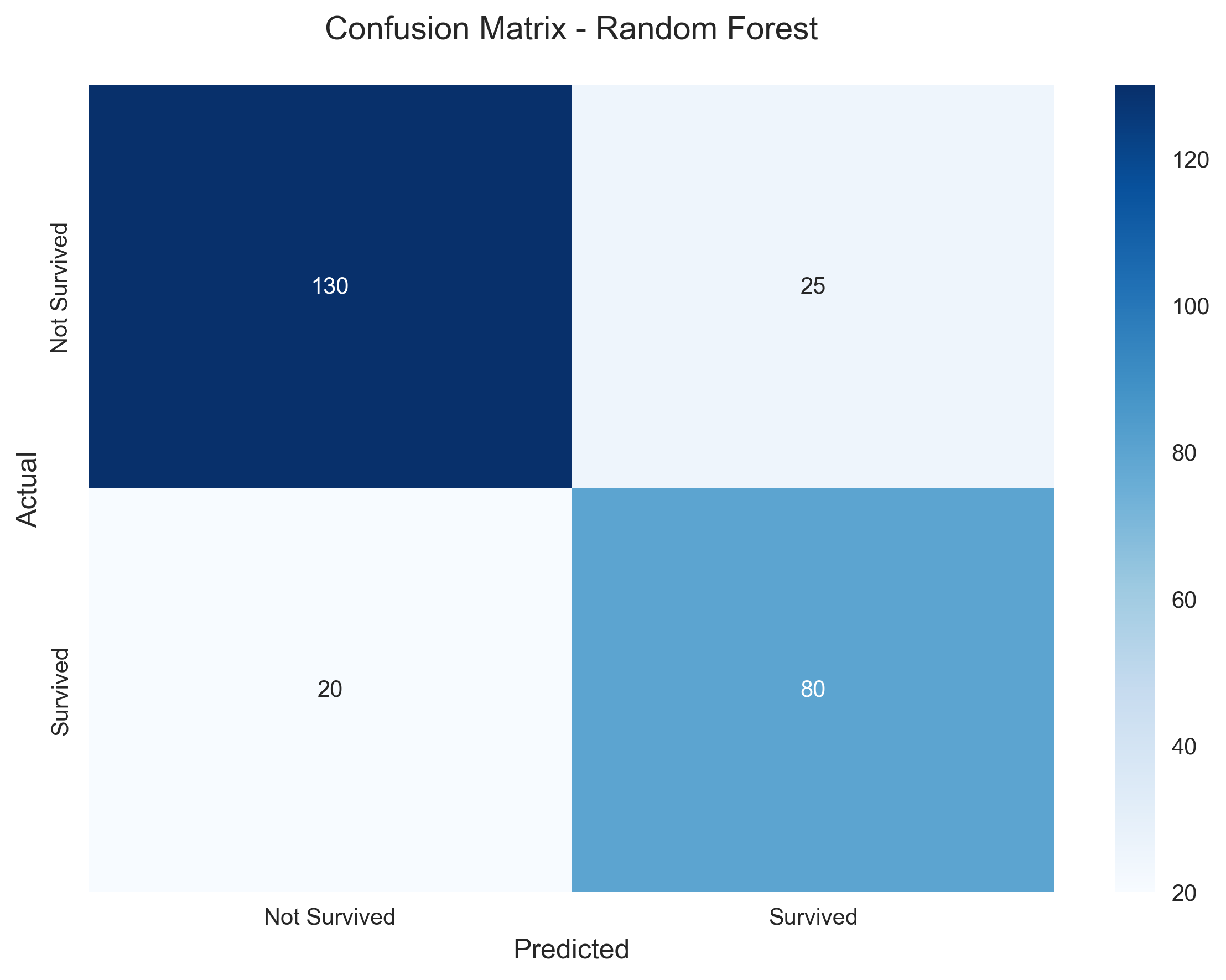
The model shows a good balance between true positives and negatives, with relatively few false positives and negatives.
Key Findings
✓ The passenger's title and gender were the most important predictors of survival.
✓ Passenger class had a significant impact on survival chances.
✓ Random Forest outperformed other models with an accuracy of 84.13%.
✓ Family size and fare were also important factors in prediction.